Ask Geth: Snapshot Acceleration

*This is part 1 series It’s a place where anyone can ask questions about Geth, and I try to answer the most voted questions each week by writing a short post. Here are the most voted questions this week: Can you share how Flat DB architecture differs from legacy architecture?*
State of Ethereum
Before we get into the acceleration architecture, let’s briefly summarize what Ethereum calls it. situation This is how it is currently stored at various levels of abstraction.
Ethereum maintains two types of state: a set of accounts; A set of save slots for each contract account. at a purely abstract perspective, both are simple key/value mappings. Account sets map addresses to nonces, balances, etc. The storage area of a single contract maps arbitrary keys defined and used by the contract to random values.
Unfortunately, although storing these key-value pairs as flat data is very efficient, verifying their correctness is computationally intractable. Every time a modification is made, all data must be hashed from scratch.
Instead of always hashing the entire dataset, you can break it down into small contiguous chunks and build a tree on top of them! The original useful data is in the leaves, and each internal node becomes a hash of everything below it. This allows only the logarithmic number of the hash to be recalculated when something is modified. This data structure actually has a name. merkle tree.
Unfortunately, we are still a bit short on computational complexity. The Merkle tree layout above is very efficient at incorporating modifications into existing data, but insertions and deletions cause chunk boundaries to shift and become invalid. every Computed hash.
Instead of blindly splitting your data set into chunks, you can use the keys themselves to organize your data in a tree format based on common prefixes! This way, insertions or deletions only change the log path from root to leaf, rather than moving all nodes. This data structure patricia wood.
Combining these two ideas, the tree layout of the Patricia tree and the hashing algorithm of the Merkle tree, we get: Muckle Patricia Tree, the actual data structure used to represent state in Ethereum. Guaranteed algebraic complexity for modifications, insertions, deletions and validations! A small addition is that the key is hashed before insertion to balance the attempts.
State storage in Ethereum
The above explanation explains why Ethereum stores state in a Merkle Patricia tree. Unfortunately, when it comes to getting what you want done quickly, all your choices are balanced out. cost of Log update and log verification is Reading logs and saving logs for every individual key. This is because all internal trie nodes must be stored individually on disk.
There are no exact numbers for the depth of the current account tree, but about a year ago it was saturated at a depth of 7. This means that all tree operations (e.g. read balance, write nonce) will reach at least 7. -8 internal nodes, thus performing at least 7-8 continuous database accesses. LevelDB also organizes data into up to 7 levels, so there’s an extra multiplier there. The final result is: Single National access is expected to expand. 25-50 random Disk access. Multiplying this by all the state reads and writes touched by every transaction in the block, we get: scary number.
(Of course, all client implementations do their best to minimize this overhead. Geth uses large memory regions to cache tree nodes and also uses in-memory pruning to avoid writing to disk nodes that are deleted after a few blocks. . This is a different case, but a blog post.)
As scary as these numbers are, is the cost of running an Ethereum node and having the ability to cryptographically verify all states at all times. But can we do better?
Not all access is created equal.
Ethereum relies on cryptographic proof of state. There is no way to avoid disk amplification to maintain the ability to verify all data. That is, we You can – and you can – Trust the data we have already verified.
You don’t need to check and re-check every status item every time you pull something from disk. Merkle Patricia trees are essential for writes, but are an overhead for reads. We can’t eliminate it, we can’t reduce it. But that’s doesn’t mean We must use it everywhere.
Ethereum nodes access state from a few different places.
- When fetching a new block, EVM code execution performs a somewhat balanced number of state reads and writes. However, denial-of-service blocks can perform much more reads than writes.
- When a node operator retrieves status, e.g. eth_call and family), EVM code execution only reads (it can also write, but it is discarded at the end and is not persisted).
- When a node is synchronizing, it digs up and requests status from remote nodes that need to be provided over the network.
Based on the access pattern above, if you can short-circuit the reads so they don’t hit the state tree, you’ll have a ton of node operations. Pretty Faster. It can also enable some new access patterns (such as state iteration) that were previously prohibitively expensive.
Of course, there are always trade-offs. Failure to remove the try will introduce additional overhead into the new acceleration structure. The question is whether the additional overhead provides enough value to warrant it.
return to roots
We built this magic Merkle Patricia tree to solve all your problems, and now you can read it. What acceleration scheme should I use to speed up rereads? Well, if you don’t need a try, there’s no need for complexity to be introduced. We can go back to the roots.
As mentioned at the beginning of this post, theoretical ideal The data store for the state in Ethereum is a simple key-value store (separate for the account and each contract). However, without the constraints of the Merkle Patricia tree, there is “nothing” preventing you from actually implementing your ideal solution!
Not long ago, Geth snapshot Acceleration Structure (not enabled by default) A snapshot is a complete view of the state of Ethereum for a specific block. In abstract implementation terms, it is a dump of all accounts and storage slots, represented as a flat key-value store.
Every time you try to access an account or storage slot, you only pay for 1 LevelDB lookup instead of 7-8 per tree. Snapshot updates are also simple in theory. After processing the block, we perform one additional LevelDB write per updated slot.
Snapshots increase writes from O(log n) to O(1 + log n) (twice the LevelDB overhead) and increase reads from O(log n) to O(1) (twice the LevelDB overhead) at the expense of increasing disk storage. ). From O(n log n) to O(n + n log n).
The devil is in the details
Maintaining a usable snapshot of the state of Ethereum is complex. The naive approach of merging changes into a snapshot works as long as the blocks come one after the other and always build on top of the last block. However, if you have a mini-reorg (even a single block), you run into problems because you can’t undo it. Persistent writes are one-way operations for simple data representation. To make matters worse, it is impossible to access the previous state (e.g. 3 blocks ago for some DApps, 64+ blocks for quick/snap sync).
To overcome this limitation, Geth’s snapshot consists of two entities. That is, a persistent disk layer that is a complete snapshot of the previous block (e.g. HEAD-128); And on top there is an in-memory diff layer tree that collects writes.
Each time a new block is processed, it creates a new in-memory diff layer containing the changes, rather than merging the writes directly into the disk layer. Once enough in-memory diff layers are stacked on top, the bottom layers begin to merge and are eventually pushed to disk. Whenever we need to read a status entry, we start at the top diff layer and keep going back until we find that entry or reach the disk.
This data representation is very powerful as it solves many problems. In-memory diff layers are assembled into a tree, so a reorg shallower than 128 blocks can select a diff layer belonging to a parent block and build forward from there. DApps and remote synchronizers that require previous states have access to the 128 most recent states. Although 128 map lookups increase cost, 128 in-memory lookups are much faster than 8 disk reads, amplified by 4x to 5x by LevelDB.
Of course, there are many problems and caveats. Without going into too many details, I will briefly list the following details:
- Self-destruct (and deletion) is a special beast because it requires short-circuiting differential layer descent.
- If there is a reorganization deeper than the persistent disk layer, the snapshot must be completely deleted and recreated. This is very expensive.
- On shutdown, the in-memory diff layer should be kept in the journal and loaded as a backup. Otherwise, the snapshot will be useless upon restart.
- It uses the bottom diff layer as an accumulator and flushes it to disk only when it exceeds some memory usage. This allows deduplicated writes to the same slot across blocks.
- Allocate read cache for the disk tier to avoid disk hits due to contracts that repeatedly access the same ancient slots.
- Using a cumulative bloom filter on an in-memory diff layer allows you to quickly detect whether an item is likely to be included in the diff or can be moved to disk immediately.
- Since the key is a hash rather than raw data (account address, storage key), it ensures that the snapshot has the same iteration order as the Merkle Patricia tree.
- Creating a persistent disk tier takes much more time than the cleanup period for the state, so even the generator must follow the chain dynamically.
The good, the bad, the ugly.
Geth’s snapshot acceleration architecture reduces state read complexity by approximately 10x. This means that read-based DoS becomes much more difficult to execute. and eth_call The call will be much faster (if not CPU bound).
Snapshots also allow for very fast state iteration of the most recent block. This was actually the main reason for building snapshots.Because it allows new creation snap synchronization algorithm. Explaining this is a whole new blog post, but Rinkeby’s latest benchmark speaks volumes.
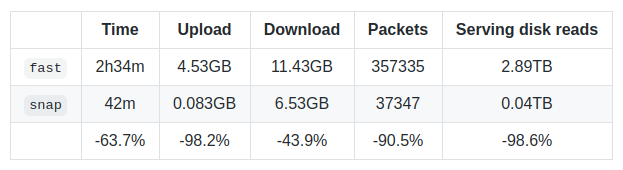
Of course, there are always trade-offs. After the initial synchronization is complete, creating an initial snapshot on mainnet takes approximately 9-10 hours (after which it will be maintained live) and requires approximately 15 GB or more of additional disk space.
What’s the ugly part? Well, it took me more than six months to feel confident enough to release a snapshot, and even now it’s lagging behind. –snapshot It needs to be flagged and still needs tweaking and polishing regarding memory usage and crash recovery.
Overall, we are very proud of these improvements. It was a huge amount of work and a huge opportunity to implement everything in the dark and hope it works out. An interesting fact is that the first version of Snap Sync (Leaf Sync) was written 2.5 years ago and has been blocked ever since because it lacked the necessary acceleration for saturation.
epilogue
I hope you enjoyed this first post. Ask about Guess. It took about twice as long to complete as I had aimed for, but I felt the topic was worth the extra time. See you next week.
(PS: I intentionally didn’t link the request/vote website to this post because I’m sure it’s temporary and I don’t want to leave broken links for posterity. I also don’t want someone buying the name and hosting something malicious for the future. .you can find it from my twitter posts.)



