
In short
- GLM-5.2 trails Claude Opus 4.8 by just 1% on FrontierSWE, a benchmark that measures autonomous engineering projects over many hours, while also outperforming GPT-5.5 on the same test. Shipped under the MIT license with no region restrictions.
- This model is built entirely on Huawei Ascend chips, without using NVIDIA hardware.
- Unsloth AI has already released a 2-bit GGUF quantization that scales the model down from 1.51TB to 238GB. You’ll still need 256GB of RAM or VRAM, but you’ll be able to run it at that point.
Z.ai released GLM-5.2 on June 16, promising top-notch performance over the already advanced GLM 5.1.
The Beijing-based institute, which has been on the U.S. entity list since January 2025, appears to be benefiting from growing concerns about the U.S. approach to AI. Over the past week, the ban on Anthropic Fable and the launch of this new model have pushed zAI’s stock price up 90% to a new all-time high.
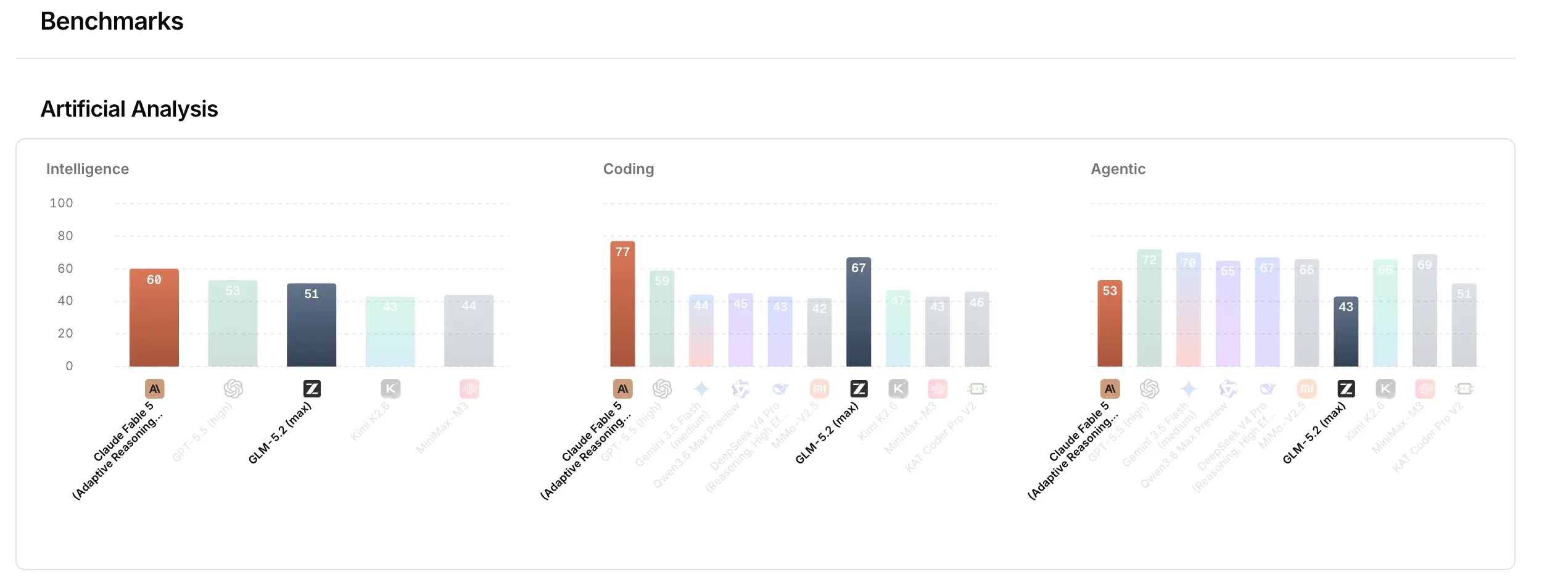
GLM 5.2 has the numbers to back up the hype.
Scored by dominance percentage on FrontierSWE (a benchmark that evaluates the ability of AI agents to complete open technology projects measured in hours, including system optimization, large-scale code composition, and applied ML research), GLM-5.2 scored 74.4 compared to Claude Opus 4.8’s 75.1. It surpassed GPT-5.5 with 72.6. In SWE-bench Pro, which tests autonomous solving of real-world GitHub problems scored by passing percentage, GLM-5.2 scored 62.1 points to GPT-5.5’s 58.6 points, beating its predecessor GLM-5.1’s 58.4 points by a wide margin.
The quality improvements make it the best open source model to date in the Artificial Analysis Intelligence Index, which aggregates the results of nine scores to assess the general quality of an AI model. OpenRouter’s benchmarks put it in the same category as the now-banned Claude Fable 5.
The hardware used to achieve this feat is another interesting part of the story. GLM-5.2 is trained on the Huawei Ascend chip. There is no Nvidia in the pipeline. Emad Mostaque, founder of Stability AI, estimated total training costs at around $25 million, which is 80% of post-training costs, which would be very affordable compared to peers.
like Decryption reported earlier this yearZ.ai was already training its image models on Huawei’s Ascend Atlas servers without a single US chip. GLM-5.2 further develops that infrastructure. It is an expert mixture model of 744 billion parameters with a real 1 million token context window, 5 times the 200K limit of GLM-5.1, and an MIT license where government guidelines mean access switches cannot be toggled.
Tokens are chunks that the model can read and create. Parameters, on the other hand, are a number of internal settings and values that determine how the model processes information and produces a response.
Who is it for and how much does it cost?
For developers, context windows are an operational change. Full repository exploration, multi-file refactoring, and long agent pipelines that previously required chunks become single-call workflows. The API price is $1.40 per $1 million input tokens and $4.40 per $1 million output tokens. This compares to the Claude Opus 4.8’s $5 input and $25 output. Coding plans start at around $18 per month and work directly within Claude Code, Cline, Kilo Code, and the most popular agent environments.
Technically, local deployment is also possible. Unsloth AI pushed 2-bit GGUF quantization, compressing the model from 1.51TB to 238GB while maintaining up to 82% accuracy.
But don’t get too excited. This means you’ll still need 256GB of integrated memory or a matching RAM/VRAM combo (up to an M4 Ultra Mac Studio or workstation with a midrange GPU and 256GB of system RAM with expert mixed offloading capabilities). It’s still a lot of money, but it’s something you can at least buy and run from home if you really want to.
We ran a quick test in GLM-5.2, asking it to build a standard game that mixes shooter and typing mechanics. The UI wasn’t the prettiest. Other models produced more polished interfaces, but the experience varied the most. There were different scenarios per wave, changing enemy types, bosses that appeared later in the run, and more.
At zero-shot settings, it produced a greater variety of game states than anything else we tested for the same task.
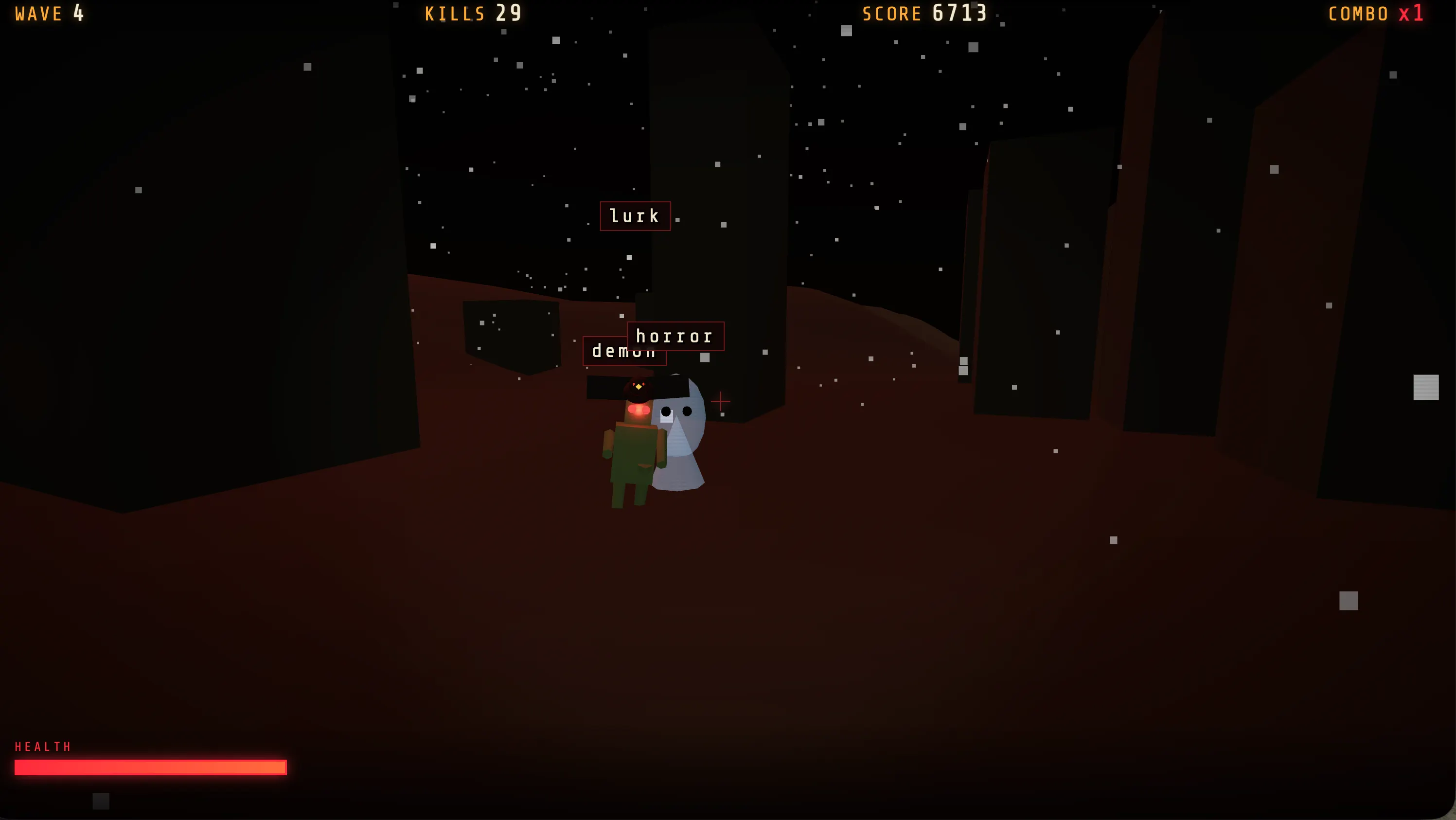
If you want to play, watch live on my Itch.io profile.
These differences point to where GLM-5.2 makes the most economic sense. For multi-shot creation workflows and agent pipelines where output variety is more important than polish, the math of open source price levels is hard to argue with. For the most difficult sustained task (SWE-Marathon, 13.0 points compared to 26.0 for Opus 4.8), the gap to the closed perimeter is still real and 13 points wider.
Open source weights are published on HuggingFace under the MIT license. Quantized weights are also available in HuggingFace. GLM Coding Plan subscribers can now switch to model string GLM-5.2 and test it for free on z.AI with some usage restrictions.
daily report newsletter
Start your day today with top news stories, original features, podcasts, videos and more.

 miners’ global hash rate share hit a new high of 26% in August, according to JPMorgan.")

