State Tree Pruning | Ethereum Foundation Blog

One of the significant issues raised during the Olympic Stress Net release process is the large amount of data that clients need to store. In just over three months of operation, and especially in the last month, the amount of data in each Ethereum client’s blockchain folder has grown to a whopping 10 to 40 GB, depending on which client you are using and whether compression is enabled. . It is important to note that this is actually a stress testing scenario where users are encouraged to dump transactions on the blockchain, paying only free test ether as transaction fees, thus resulting in transaction throughput levels that are several times higher than Bitcoin. Still, in many cases, it’s a legitimate concern for users who don’t have hundreds of gigabytes of free space to store other people’s transaction history.
First of all, let’s look at why the current Ethereum client database is so large. Unlike Bitcoin, Ethereum has the property that every block contains something called a “state root.” A special kind of Merkle tree Saves the overall state of the system. All account balances, contract stores, contract codes and account nonce are located inside.
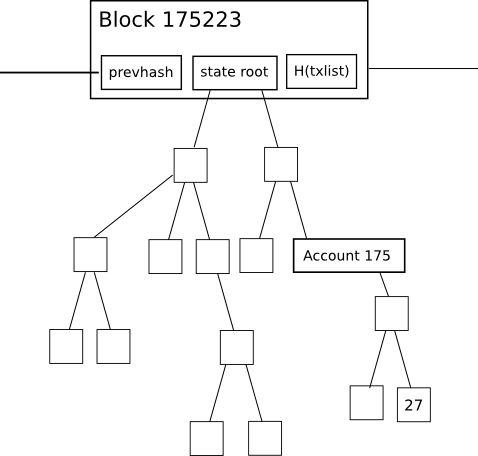
The purpose of this is simple. A node, given only the last block, can very quickly “synchronize” with the blockchain by simply downloading it without processing past transactions, with the assurance that the last block is in fact the most recent block. The remaining tree of network nodes (the proposed hash lookup wire protocol message This will facilitate this), check that all the hashes match, and then proceed from there to ensure that the tree is correct. In a fully decentralized context, this would likely be done via an advanced version of Bitcoin’s header-first verification strategy, roughly equivalent to:
- Download as many block headers as the client can get.
- Determines the header at the end of the longest chain. From that header, we move back 100 blocks for safety and call the block at that location P.100(H) (“100 Greatest Grandparents”)
- Download the state tree from the state root of P.100using (H) hash lookup The opcode (after the first round or two can be parallelized across as many peers as desired) ensures that all parts of the tree match.
- Proceed normally from there.
For light clients, the state root is much more advantageous. You can instantly check the exact balance and status of all your accounts by simply making a request to the network. specific point There is no need to follow Bitcoin’s multi-stage 1-of-N, “request all transaction outputs, then request all transactions that consume those outputs and take the remainder” light client model.
However, this simple implementation of the state tree mechanism has significant drawbacks. This means that intermediate nodes in the tree significantly increase the amount of disk space required to store all the data. Take a look at the following diagram to see why:
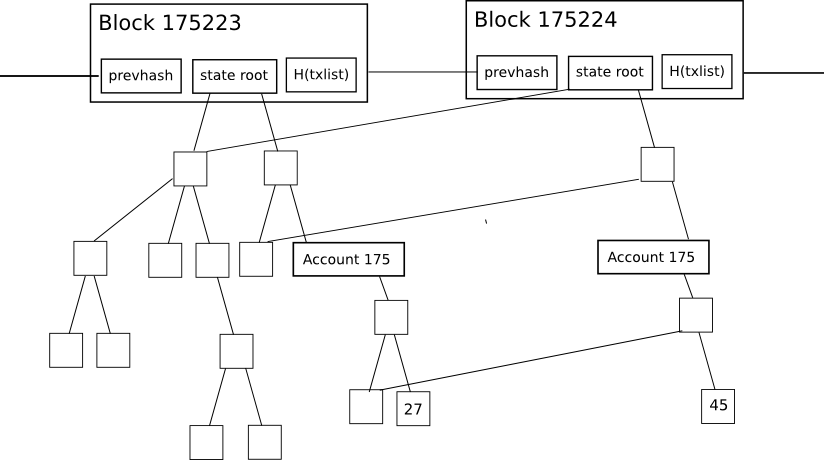
Changes to the tree during each individual block are fairly small, and the magic of the tree as a data structure is that most of the data can only be referenced twice without being copied. But even so, each time the state changes, a logarithmically large number of nodes (e.g. ~5 for 1000 nodes, ~10 for 1000000 nodes, ~15 for 1000000000 nodes) need to be stored twice. One version The old tree has one version and the new tree has one version. Eventually, as the nodes process all blocks, we can expect the total disk space utilization, in computer science terms, to be approximately: O(n*log(n))where N Transaction load. In reality, the Ethereum blockchain is only 1.3 GB, but the database containing all these additional nodes would be 10 to 40 GB in size.
So what can we do? One way to fix the previous version is to implement header-first synchronization, which essentially resets new users’ hard disk consumption to zero and allows users to resynchronize every 1-2 months to keep hard disk consumption low. It’s a rather ugly solution. An alternative approach is to implement: pruning the main tree: essentially used Reference counting It tracks when a tree’s nodes (here we use “node” in computer science terms to mean “a piece of data somewhere in a graph or tree structure” rather than “a computer on a network”) fall off the tree. At that point, place the node on “death row.” Unless the node is somehow reused by the next node. X Blocks, e.g. x = 5000), after that number of blocks, the node must be permanently deleted from the database. Basically we store tree nodes that are part of the current state, we also store recent history, but we do not store history older than 5000 blocks.
X Although it should be set as low as possible to save space. X If it is too low, robustness will be reduced. Once this technology is implemented, nodes will not be able to revert further than: X Essentially it blocks the sync without completely restarting it. Now let’s see how this approach can be fully implemented, taking into account all special cases.
- When processing blocks with numbers N, we keep track of all nodes (state, tree and receiving tree) whose reference count drops to 0. We place the hashes of these nodes into a “death row” database in some kind of data structure so that we can later retrieve the list by block number (specifically the block number). No + X), marks the node database item itself as deletable from the block. No + X.
- When a node on death row is restored (a practical example is when account A acquires a certain balance/nonce/code/repository combination) FSwitch to another value gAnd Account B acquisition status F While the node is F death row), increase the reference count back to 1. If that node is deleted again in a future block middle (with M > N), and then put back into the death row of a future block to be deleted from the block. M+X.
- When we get to the processing block No + XFetch the list of hashes logged back during blocking. N. Check which node is associated with each hash. If the node is still marked for deletion During that specific block (i.e. it hasn’t been restored and, importantly, it hasn’t been restored and is then marked again for deletion) later), delete it. It also purges the hash list in the death row database.
- Sometimes the new head of the chain is not positioned above the old head and the block has to be reverted. In these cases, all changes to the reference count must be kept in a database (this is the “journal”). journaling file system; It is essentially an ordered list of changes. When reverting a block, it deletes the list of death rows created when creating that block and undoes any changes made according to the journal (deletes the journal when done).
- When processing a block, we delete the journal from the block. N-X; you can’t turn back X Since you have blocks anyway, a log is unnecessary (if you keep one, it would actually defeat the whole purpose of pruning).
Once this is done, the database should only store the state nodes associated with the last node. X So you’ll still get all the information you need from that block, but nothing more. In addition to this, there are additional optimizations. Especially after X Blocks, transactions and receipt trees must be completely deleted, and even blocks may be deleted. However, there is an important argument for maintaining some subset of “archive nodes” that store absolutely everything for the rest of the network to acquire. This is the data you need.
Now, how much savings will this bring us? As it turns out, there are quite a few! Especially if we choose the ultimate reckless path and X = 0 (i.e. completely losing all ability to handle single block forks and storing no history at all) The size of the database essentially becomes the size of the state. Even now, this value (this data was collected at block 670000) amounts to about 40MB, mostly consisting of: An account like this If your save slot is full to deliberately spam the network. In ~ x = 100000, most of the growth occurs in the last hundred thousand blocks, and the additional space required to store the journal and death row list makes up the remaining difference, so by default the current size is 10-40 GB. For all values in between, you can expect disk space growth to be linear, e.g. x = 10000 It will take about 90% to get to almost 0.)
You can also pursue a hybrid strategy. block it but not all State Tree Node; In this case, you would need to add approximately 1.4 GB to store the block data. It is important to note that fast block times are not the cause of blockchain size. Currently the block headers from the last 3 months take up about 300MB and the rest are transactions from the last 1 month, so we can expect transactions to continue to dominate if usage is high. This means that light clients must clean up block headers to survive low memory situations.
The strategy described above has been implemented in very early alpha form. PS; Because this storage expansion is a mid-term issue rather than a short-term scalability issue, it will be implemented appropriately across all clients in due course after Frontier launches.

 ETF could generate up to billion in demand as the yuan falls, Matrixport says.")

